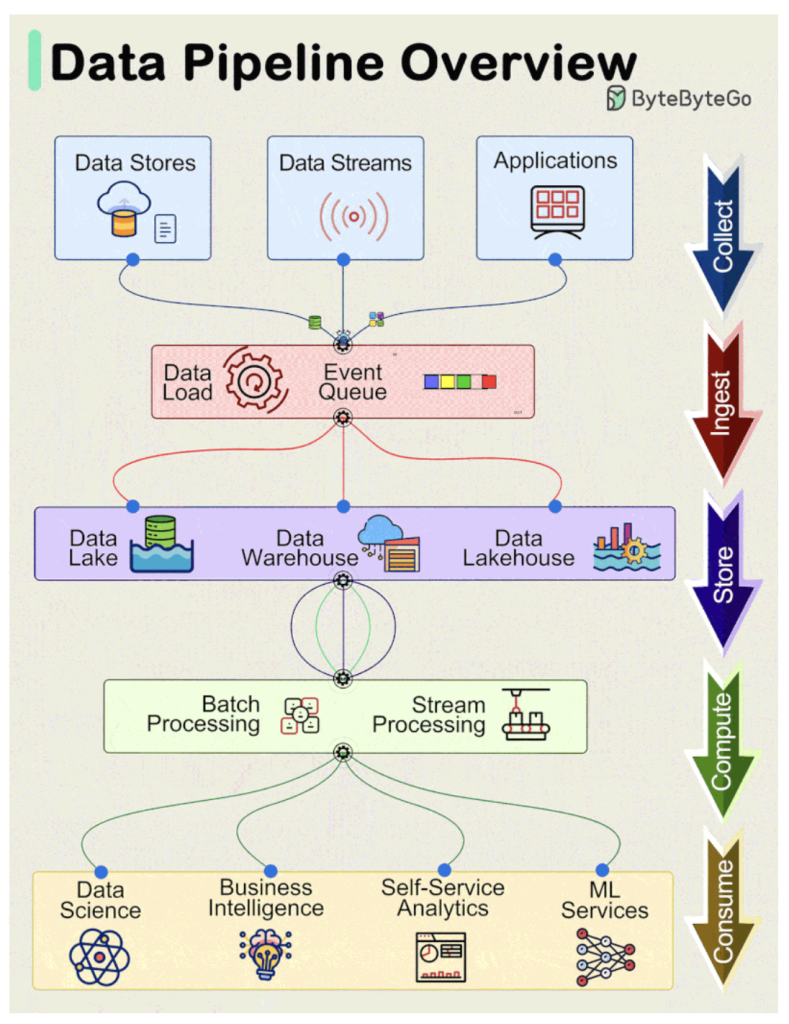
Les pipelines de données sont un élément fondamental de la gestion et du traitement efficace des données dans les systèmes modernes. Ces pipelines englobent généralement 5 phases prédominantes : Collecter, Ingérer, Stocker, Calculer et Consommer.
- Collecter :
Les données sont acquises à partir de magasins de données, de flux de données et d’applications, provenant à distance d’appareils, d’applications ou de systèmes d’entreprise. - Ingérer :
Au cours du processus d’ingestion, les données sont chargées dans les systèmes et organisées dans des files d’attente d’événements. - Stockage :
Après l’ingestion, les données organisées sont stockées dans des entrepôts de données, des lacs de données et des entrepôts de données, ainsi que dans divers systèmes tels que des bases de données, afin d’assurer le stockage après l’ingestion. - Calculer :
Les données sont agrégées, nettoyées et manipulées pour se conformer aux normes de l’entreprise, y compris des tâches telles que la conversion de format, la compression des données et le partitionnement. Cette phase fait appel à des techniques de traitement par lots et par flux. - Consommation :
Les données traitées sont mises à disposition pour être consommées par le biais d’outils d’analyse et de visualisation, de magasins de données opérationnels, de moteurs de décision, d’applications orientées utilisateur, de tableaux de bord, de services de science des données et d’apprentissage automatique, de veille stratégique et d’analyse en libre-service.
L’efficience et l’efficacité de chaque phase contribuent au succès global des opérations basées sur les données au sein d’une organisation.
Leave a Reply